
Large Language Model (LLM) machine learning technology is proliferating rapidly, with multiple competing open-source and proprietary architectures now available. In addition to the generative text tasks associated with platforms such as ChatGPT, LLMs have been demonstrated to have utility in many text-processing applications—ranging from assisting in the writing of code to categorization of content.
SophosAI has researched a number of ways to use LLMs in cybersecurity-related tasks. But given the variety of LLMs available to work with, researchers are faced with a challenging question: how to determine which model is the best suited for a particular machine learning problem. A good method for selecting a model is to create benchmark tasks – typical problems that can be used to assess the capabilities of the model easily and quickly.
Currently, LLMs are evaluated on certain benchmarks, but these tests only gauge the general abilities of these models on basic natural language processing (NLP) tasks. The Huggingface Open LLM (Large Language Model) Leaderboard utilizes seven distinct benchmarks to evaluate all the open-source models accessible on Huggingface.
However, performance on these benchmark tasks may not accurately reflect how well models will work in cybersecurity contexts. Because these tasks are generalized, they might not reveal disparities in security-specific expertise among models that result from their training data.
To overcome that, we set out to create a set of three benchmarks based on tasks we believe are fundamental perquisites for most LLM-based defensive cybersecurity applications:
- Acting as an incident investigation assistant by converting natural language questions about telemetry into SQL statements
- Generating incident summaries from security operations center (SOC) data
- Rating incident severity
These benchmarks serve two purposes: identifying foundational models with potential for fine-tuning, and then assessing the out-of-the-box (untuned) performance of those models. We tested 14 models against the benchmarks, including three different-sized versions of both Meta’s LlaMa2 and CodeLlaMa models. We chose the following models for our analysis, selecting them based on criteria such as model size, popularity, context size, and recency:
| Model Name | Size | Provider | Max. Context Window |
| GPT-4 | 1.76T? | OpenA! | 8k or 32k |
| GPT-3.5-Turbo | ? | 4k or 16k | |
| Jurassic2-Ultra | ? | AI21 Labs | 8k |
| Jurassic2-Mid | ? | 8k | |
| Claude-Instant | ? | Anthropic | 100k |
| Claude-v2 | ? | 100k | |
| Amazon-Titan-Large | 45B | Amazon | 4k |
| MPT-30B-Instruct | 30B | Mosaic ML | 8k |
| LlaMa2 (Chat-HF) | 7B, 13B, 70B | Meta | 4k |
| CodeLlaMa | 7B, 13B, 34B | 4k |
On the first two tasks, OpenAI’s GPT-4 clearly had the best performance. But on our final benchmark, none of the models performed accurately enough in categorizing incident severity to be better than random selection.
Task 1: Incident Investigation Assistant
In our first benchmark task, the primary objective was to assess the performance of LLMs as SOC analyst assistants in investigating security incidents by retrieving pertinent information based on natural language queries—a task we’ve previously experimented with. Evaluating LLMs’ ability to convert natural language queries into SQL statements, guided by contextual schema knowledge, helps determine their suitability for this task.
We approached the task as a few-shot prompting problem. Initially, we provide the instruction to the model that it needs to translate a request into SQL. Then, we furnish the schema information for all data tables created for this problem. Finally, we present three pairs of example requests and their corresponding SQL statements to serve as examples for the model, along with a fourth request that the model should translate to SQL.
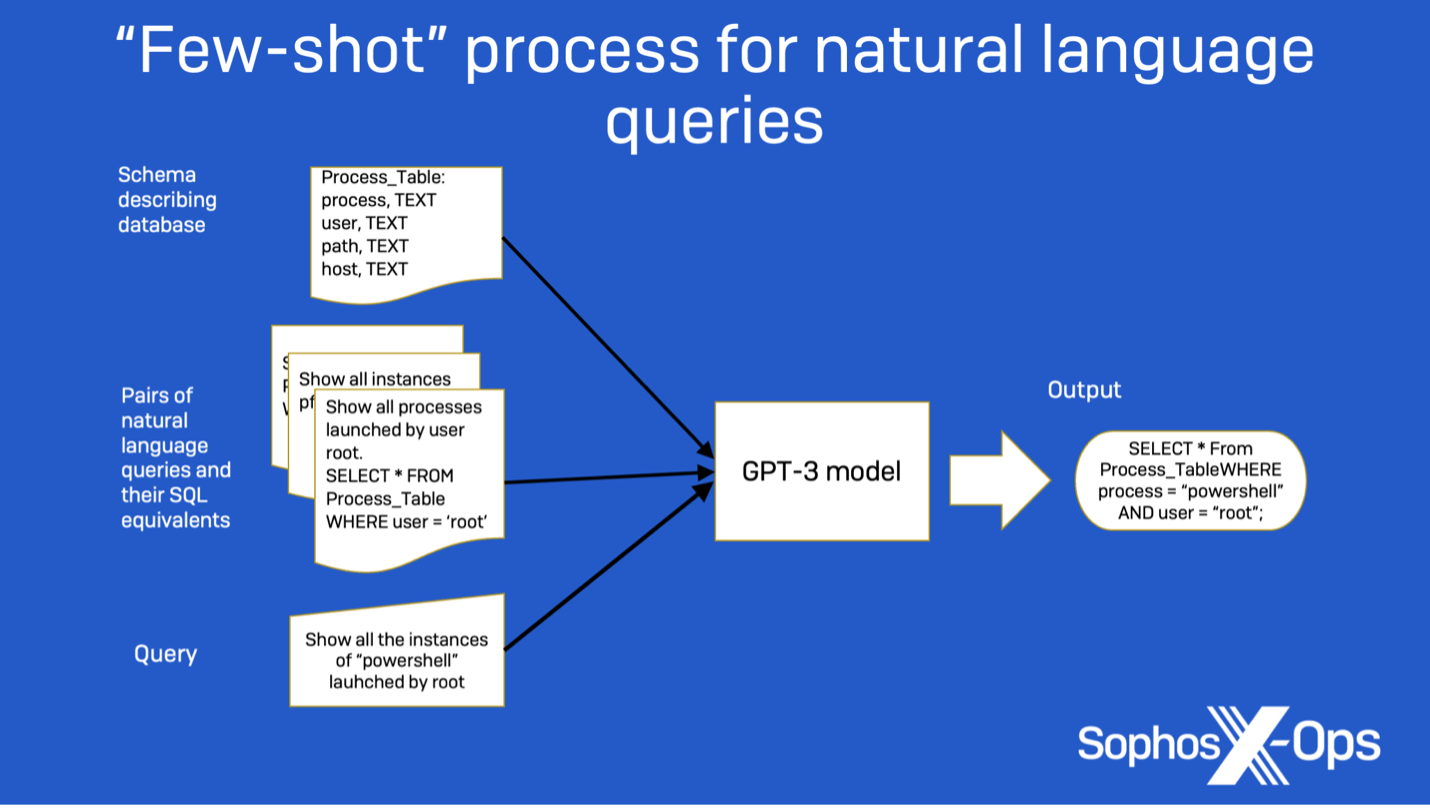
An example prompt for this task is shown below:
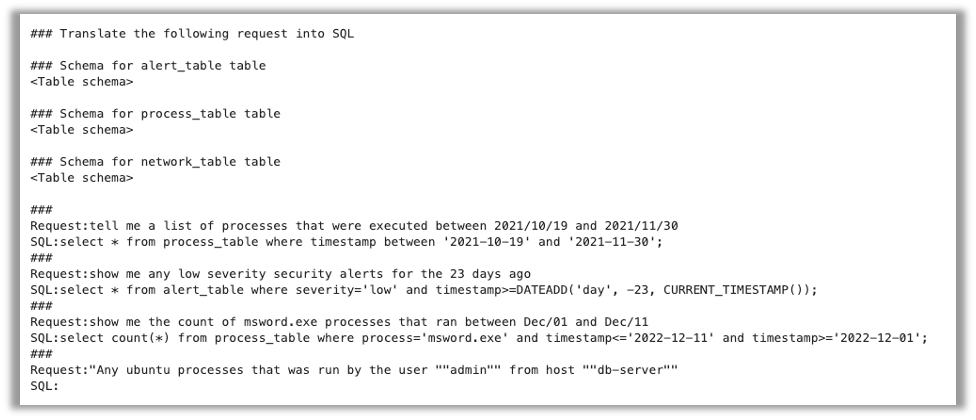
The accuracy of the query generated by each model was measured by first checking if the output matched the expected SQL statement exactly. If the SQL was not an exact match, we then ran the queries against the test database we created and compared the resulting data sets with the results of the expected query. Finally, we passed the generated query and the expected query to GPT-4 to evaluate query equivalence. We used this method to evaluate the outcomes of 100 queries for each model.
Results
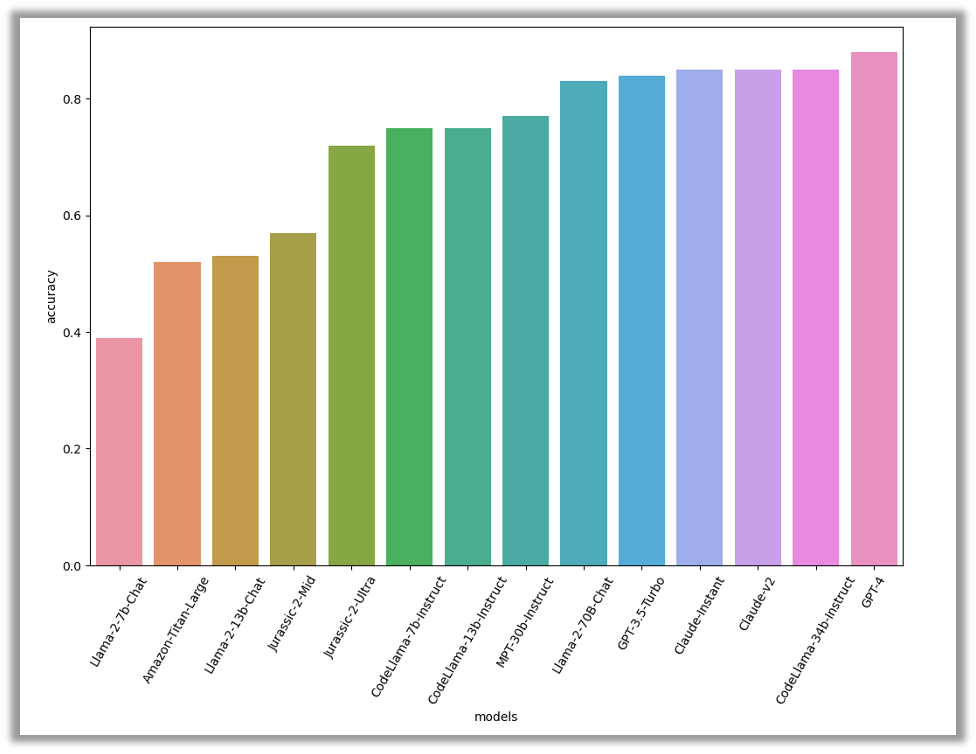
According to our assessment, GPT-4 was the top performer, with an accuracy level of 88%. Coming in closely behind were three other models: CodeLlama-34B-Instruct and the two Claude models, all at 85% accuracy. CodeLlama’s exceptional performance in this task is expected, as it focuses on generating code
Overall, the high accuracy scores indicate that this task is easy for the models to complete. This suggests that these models could be effectively employed to aid threat analysts in investigating security incidents out of the box.
Task 2: Incident Summarization
In Security Operations Centers (SOCs), threat analysts investigate numerous security incidents daily. Typically, these incidents are presented as a sequence of events that occurred on a user endpoint or network, related to suspicious activity that has been detected. Threat analysts utilize this information to conduct further investigation. However, this sequence of events can often be noisy and time-consuming for the analysts to navigate through, making it difficult to identify the notable events. This is where large language models can be valuable, as they can assist in identifying and organizing event data based on a specific template, making it easier for analysts to comprehend what is happening and determine their next steps.
For this benchmark, we use a dataset of 310 incidents from our Managed Detection and Response (MDR) SOC, each formatted as a series of JSON events with varying schemas and attributes depending on the capturing sensor. The data was passed to the model along with instructions to summarize the data and a predefined template for the summarization process.

We used five distinct metrics to evaluate the summaries generated by each model. First, we verified that the incident descriptions generated successfully extracted all the pertinent details from the raw incident data by comparing them to “gold standard” summaries—descriptions initially generated using GPT-4 and then improved upon and corrected with the help of a manual review by Sophos analysts.

If the data extracted did not completely match, we measured how far off all the extracted details were from the human-generated reports by calculating the Longest Common Subsequence and Levenshtein distance for each extracted fact from the incident data, and deriving an average score for each model. We also evaluated the descriptions using the BERTScore metric, a similarity score using OpenAI’s ADA2 model, and the METEOR evaluation metric.
Results
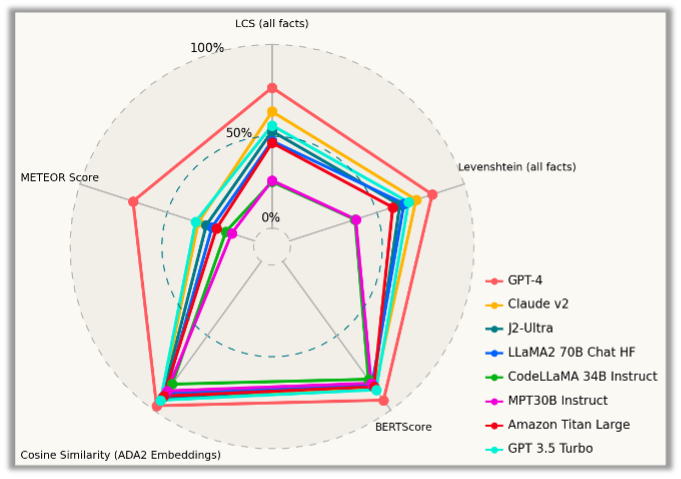
GPT-4 again stands out as the clear winner, performing significantly better than the other models in all aspects. But GPT-4 has an unfair advantage in some qualitative metrics—especially the embedding-based ones—because the gold standard set used for evaluation was developed with the help of GPT-4 itself.
Among the other models, the Claude-v2 model and GPT 3.5 Turbo were among the top performers in the proprietary model space; the Llama-70B model is the best performing open-source model. However, we also observed that the MPT-30B-Instruct model and the CodeLlama-34B-Instruct model face difficulties in producing good descriptions.
The numbers don’t necessarily tell the full story of how well the models summarized events. To better grasp what was going on with each model, we looked at the descriptions generated by them and evaluated them qualitatively. (To protect customer information, we will display only the first two sections of the incident summary that was generated.)
GPT-4 did a respectable job of summarization; the summary was accurate, though a little verbose. GPT-4 also correctly extracted the MITRE techniques in the event data. However, it missed the indentation used to signify the difference between the MITRE technique and tactic.

Llama-70B also extracted all the artifacts correctly. However, it missed a fact in the summary (that the account was locked out). It also fails to separate the MITRE technique and tactic in the summary.

J2-Ultra, on the other hand, did not do so well. It repeated the MITRE technique three times and missed the tactic completely. The summary, however, seems very concise and on point.
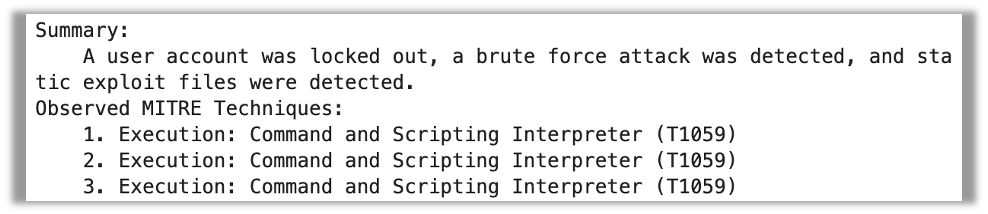
MPT-30B-Instruct fails completely in following the format, and just produces a paragraph summarizing what it sees in the raw data.

While many of the facts extracted were correct, the output was a lot less helpful than an organized summary following the expected template would have been.
CodeLlaMa-34B’s output was totally unusable—it regurgitated event data instead of summarizing, and it even partially “hallucinated” some data.
Task 3: Incident Severity Evaluation
The third benchmark task we assessed was a modified version of a traditional ML-Sec problem: determining if an observed event is either part of harmless activity or an attack. At SophosAI, we utilize specialized ML models designed for evaluating specific types of event artifacts such as Portable Executable files and Command lines.
For this task, our objective was to determine if an LLM can examine a series of security events and assess their level of severity. We instructed the models to assign a severity rating from five options: Critical, High, Medium, Low, and Informational. Here is the format of the prompt we provided to the models for this task:

The prompt explains what each severity level means and provides the same JSON detection data we used for the previous task. Since the event data was derived from actual incidents, we had both the initial severity assessment and the final severity level for each case. We evaluated the performance of each model against over 3300 cases and measured the results.
The performance of all LLMs we tested was evaluated using various experimental setups, but none of them demonstrated sufficient performance better than random guessing. We conducted experiments in a zero-shot setting (shown in blue) and a 3-shot setting (shown in yellow) using nearest neighbors, but neither experiment reached an accuracy threshold of 30%.
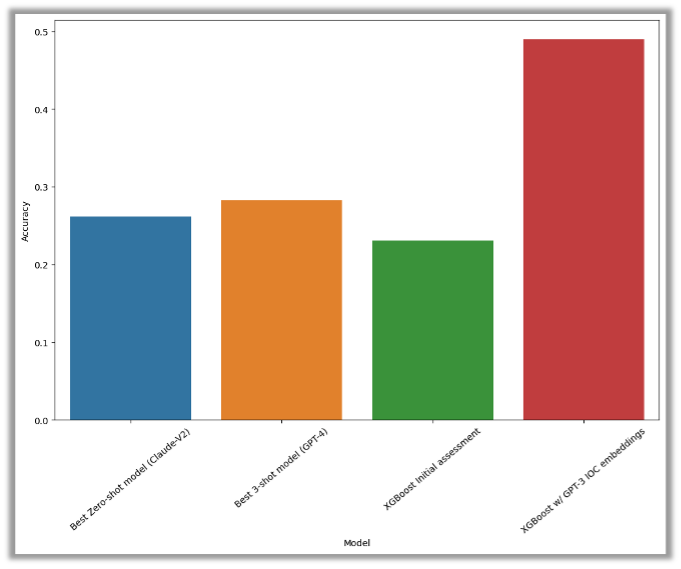
As a baseline comparison, we used an XGBoost model with only two features: the initial severity assigned by the triggering detection rules and the type of alert. This performance is represented by the green bar.
Furthermore, we experimented with applying GPT-3-generated embeddings to the alert data (represented by the red bar). We observed significant improvements in performance, with accuracy rates reaching 50%.
We found in general that most models are not equipped to perform this kind of task, and often have trouble sticking to the format. We saw some funny failure behaviors—including generating additional prompt instructions, regurgitating detection data, or writing code that produces the severity label as output instead of just producing a label.
Conclusion
The question of which model to use for a security application is a nuanced one that involves numerous, varied factors. These benchmarks offer some information for starting points to consider, but don’t necessarily address every potential problem set.
Large language models are effective in aiding threat hunting and incident investigation. However, they would still require some guardrails and guidance. We believe that this potential application can be implemented using LLMs out of the box, with careful prompt engineering.
When it comes to summarizing incident information from raw data, most LLMs perform adequately, though there is room for improvement through fine-tuning. However, evaluating individual artifacts or groups of artifacts remains a challenging task for pre-trained and publicly available LLMs. To tackle this problem, a specialized LLM trained specifically on cybersecurity data might be required.
In terms of pure performance terms, we saw GPT-4 and Claude v2 did best across the board on all our benchmarks. However, the CodeLlama-34B model gets an honorary mention for doing well on the first benchmark task, and we think it is a competitive model for deployment as a SOC assistant.
About the authors
Salma Taoufiq is a Senior Data Scientist at Sophos, working at the intersection of machine learning and cybersecurity. Currently, she is conducting research on the integration of machine learning systems within security analyst workflows and devising cutting-edge models for malware detection.
Ayarsh Kyadige



